Operational Excellence - Well Architected Framework for Serverless Applications (Pillar 1)

Developer Advocate at AWS | Serverless <3
In this blog post I will share with you all the videos related to the first pilar of the Well Architected Framework for Serverless applications.
If you don't know what the Well Architected Framework (WAF) is? WAF is a framework designed by AWS. It collects all the best practices for developing and running cost efficient applications in the cloud.
What is the Operational Excellence pillar about?
This pillar focus on developing and running workloads effectively, gain insights on your operations, and improve your operations over time.
This pillar talks a lot about DevOps practices, infrastructure as code, automatization, and observability.
Some of the design principles for this pillar are:
- perform operations as code
- make frequent, small and reversible changes
- review and refine operations procedures frequently
- anticipate and learn from failure
Best practices
There are four best practices areas for the Operation Excellence in the cloud. And there are questions to address each of the areas. I like to call these areas, steps as you need to address them in a particular order.
- Organize: In this step you share your business goals and priorities with your team. By the end everybody knows their responsibilities.
- Prepare: In this step you design your workload, so it provides the necessary information so you can understand its state. You plan how changes are managed and how they flow from end to end.
- Operate: This step is all about the operations of the operational excellence.
- Evolve: Keep on learning, sharing and continuously improving.
I organized this blog post based in those 4 areas.
Organization
This area is all about understanding the responsibilities of the team and team members, and about having clear priorities.
This area focuses on answering these questions:
- OPS1: How do you determine what your priorities are?
- OPS2: How do you structure your organization to support your business outcomes?
- OPS3: How does your organizational culture support your business outcomes?
Make sure that you identify owners for each application, components or process. Having owners is critical to improve the performance of the component.
Have a clear understanding of the business value for each component and why we own it. Create mechanisms for handling changes in the components, and assign owners to them.
Then evaluate risks and keep them in track for each of your components.
Make sure that people feel empowered to experiment and create mechanisms where experimenting is safe. For example, make it difficult for your developers to take down production, so they can deploy on their own terms and see the results right away.
Keep your teams trained and increase their understanding of how their choices impact the workload.
Prepare
In this area, you will design your workload so it can provide all the information you need to understand it state.
This area focuses on answering these questions:
- OPS4: How do you design your workload so that you can understand its state?
- OPS5: How do you reduce defects, ease remediations and improve flow to production?
- OPS6: How do you mitigate deployment risks?
- OPS7: How do you know that you are ready to support a workload?
This area is about design and planning.
Lot of issues that can be solved by having CI/CD (continuos integration / continuos delivery) in place:
- Adopt approaches that enable fast feedback from change to production and fast recovery.
- Emphasis small, reversible and frequent changes.
- Use a consisten process to go live or preform changes in prod
Other things that are solved with good DevOps processes, like:
- have run books to document routine activities
- Have playbooks to guide issue resolutions
- use infrastructure as code and different stages
Operate
In this area is all about the operations of the Operational Excellence.
This is the area were it gets practical to your AWS environment. I will show you many good practices in action.
Questions that are answer here:
- OPS8: How do you understand the health of your workload?
- OPS9: How do you understand the health of your operations?
- OPS10: How do you manage workload and operations events?
In the Serverless Lens 2 more questions are added.
- How do you understand the health of your serverless application?
- How do you approach application lifecycle management?
In my opinion, answering these 2 last questions will help us to answer part of OPS8 to 10.
How do you understand the health of your serverless application?
This can be done with Metrics, Logs and Tracing: the Observability triad.
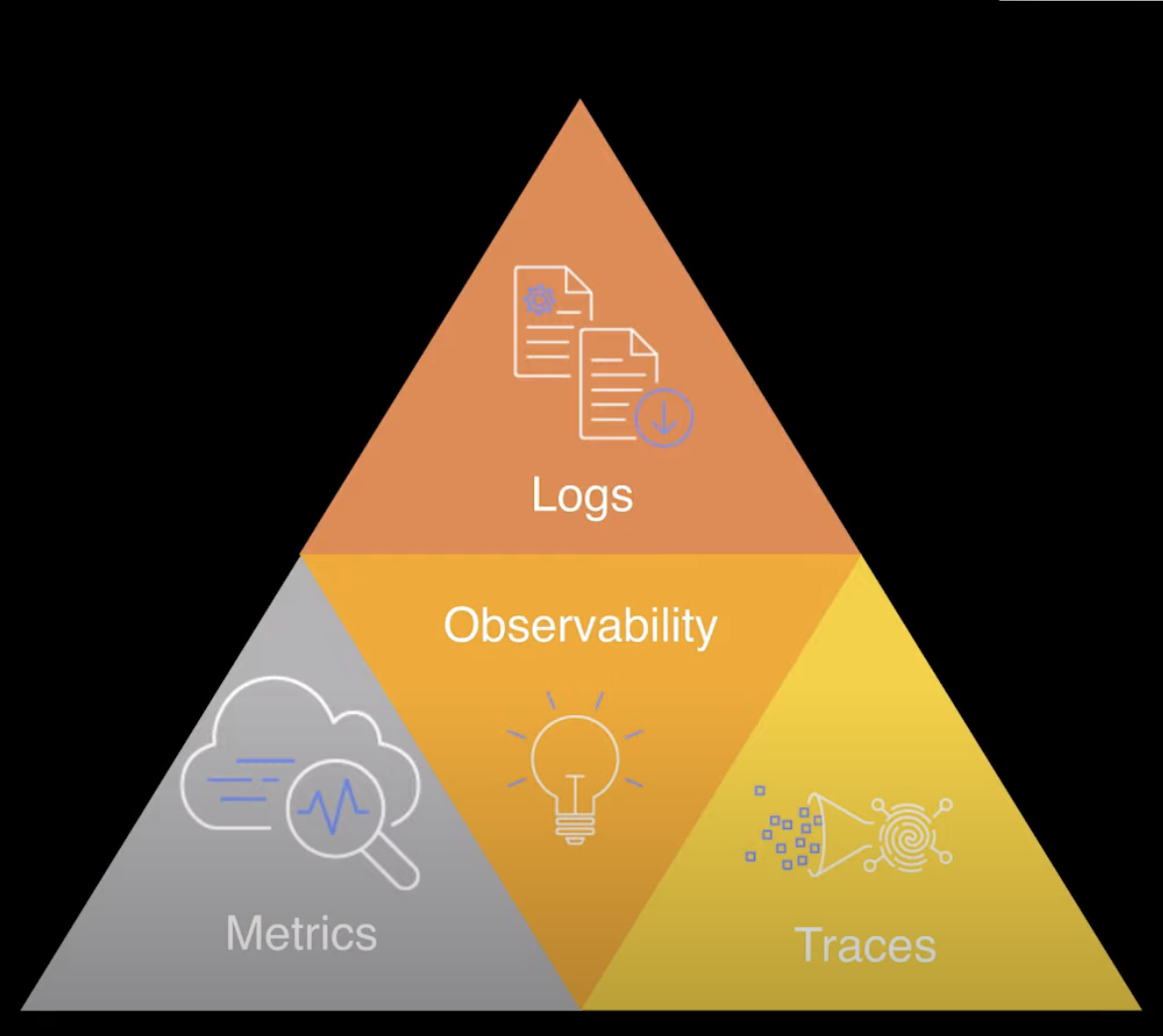
You need to implement all these in our serverless applications to be able to understand the health of our application.
- Logs are time stamped record of events with information about that discrete moment in time.
- Metrics gather a numerical data about things we want to track in our application.
- Traces are a single transaction end to end, how this transaction journey your whole application.
So how you implement all these things when using AWS?
For logs we use CloudWatch logs, CloudWatch insights and structure logging libraries.
For Metrics you can use CloudWatch metrics, the CloudWatch dashboard and CloudWatch alarms
For traces you can use AWS X-Ray and CloudWatch service lens.
How do you approach application lifecycle management?
Applications tend to have a similar lifecycle. First you code and build prototypes, new features, experiments. Then you build and deploy into a some kind of safe environment were you can run tests, and then finally you deploy to production. There can be more o less stages and environments in place, and this process can be or not automated.
This question covers many topics related to each other:
- Infrastructure as code
- CICD pipelines
- Deployment environments
- Application configuration management
- Testing
For most of the topics in this list, are covered in the the session I recorded for AWS reInvent 2020.
For IaC, I have many videos talking about AWS CloudFormation, AWS SAM, AWS CDK, Amplify and others. You can check this playlist
For CI/CD pipelines and creating different environments, I have many videos on Code Pipelines built with CloudFormation, CDK pipelines, AWS SAM pipelines with Github, Gitlab pipelines and AWS Amplify CICD. And more are coming in the future for sure. Here you can find the playlist
In those videos you can learn how to create multiple environments and how to automate your deployment from your computer to production.
Also I created videos related to deployment strategies for your applications, such as Canary and Linear deployments and how to do it with CodeDeploy.
For Application configuration management, you need to learn about Parameter Store, KMS to encrypt the parameters, the Secret Store, and also how to juggle the application in an automated way in your application. You can achieve all these, using a service like AppConfig or by having environmental variables in your applications. Check the playlist for those videos
And finally testing. There are so many places where we can test in a serverless application. It is important to learn to perform all the different kind of tests in the right level of our application.
For example, when we talk about source we do code reviews and pull requests. For that you can use a service such as Code Guru, if you have Lambda functions running in Java o libraries that perform similar checks in your remote repos.
For the build phase we run all the linting and unit testing of our application. Here is not only the code but the infrastructure that can be tested.
Then you need to focus in integration tests. Integration tests are tests that run in environments in the cloud with real cloud services. You can use Lambda functions for example to run integration tests.
Also you can do load testing of your serverless applications with services like artillery. That allow you to create simulations load in your application and see how the application responds to the high load.
To deploy your application safetely into production, there are many deployment strategies using AWS CodeDeploy. CodeDeploy runs integration tests before and after deploying a new version of your application to a specific environment.
For all the things mentioned here, there is a playlist on how to implement everything in AWS.
Evolve
This phase is about learning and continue improving everything you have built in the past
It answers the question
- OPS11 : How do you evolve operations?
In this step you need to make time to make your operations better. There are always things that can improve.
Also this phase talks about creating feedback mechanisms to learn about services going down or with poor performance. Also mechanisms to share these learnings across the whole organization.
It also talks about how you save this lessons and monitor the data and metrics you use to create them.
I will add here that a great practice to evolve Operational Excellence is running regular Game Days in your organization. Game days allows you to test all the things listed in this post and see all your mechanisms in practice. Game day tests your process and systems in action and finds when process can goes wrong.
Also in this step you can think about exploring Chaos Engineering, and to create automatic tests for your organization.
I also have this post as a video if you prefer to watch instead than to read




