Building data streaming applications with Amazon Kinesis and serverless

Developer Advocate at AWS | Serverless <3
Welcome to this comprehensive guide on using Amazon Kinesis for building serverless data streaming applications. This detailed guide will cover various aspects, ranging from what are data streaming applications, to understand the different services offered in the Kinesis family, to deep dives on Amazon Kinesis Data Streams with Lambda, Event Source Mapping, integrations with Kinesis Data Streams and Pipes and more advanced concepts.
The guide is divided into five sections, each addressing different topics:
Section 1: Introduction to Data Streaming applications: In this section, you will learn what are data streaming applications, some advanced patterns, and get a short introduction about Amazon Kinesis family of service.
Section 2: Amazon Kinesis Data Streams: The second section provides an general view of the fundamental concepts of Kinesis Data Streams.
Section 3: Amazon Kinesis Data Streams and AWS Lambda: The third section provides an in-depth understanding of the fundamental concepts of Kinesis Data Streams when paired with AWS Lambda to consume and put records into the stream.It caters to both beginners and experts, delving into the inner workings of this service.
Section 4: Kinesis Data Streams and Amazon EventBridge Pipes: In the fourth section, you will discover a new way to consume records in real-time from your streams. How EventBridge Pipes can help you out and why it is an alternative to AWS Lambda in many cases.
Section 5: Amazon Kinesis Firehose: The final section goes into details on using Amazon Kinesis Firehose, how to build a simple pipeline, and how to use AWS Lambda to transform records in almost real-time.
So, without further ado, let's dive into the world of Amazon Kinesis and unlock its full potential!
Happy learning!
1-Introduction to Data Streaming
To understand data streaming, you first need to grasp the traditional data processing approach. In the past, data was often stored in databases and processed in batches. However, this method had its limitations, especially when dealing with massive amounts of data in real-time scenarios.
Data streaming, on the other hand, enables continuous data flow, processing data in real-time as it arrives and does real time alerts, actions, analytics or ML processing. Think of it as a never-ending river of information, constantly being analysed and acted upon.
Use Cases of Data Streaming
Now that you understand the significance of data streaming, let's explore some of the compelling use cases where it truly shines. Data streaming finds applications in various industries.
For instance, in the Internet of Things (IoT) realm, sensors continuously stream data from connected devices, allowing real-time monitoring and analysis of critical systems.
Financial institutions benefit from data streaming to process high-frequency trading data swiftly and detect fraudulent activities in real-time.
Social media platforms use data streaming to track trending topics, analyse sentiments, and provide personalised content to users.
Data streaming platforms
At the core of data streaming are streaming platforms like Apache Kafka, Apache Flink and AWS Kinesis. These platforms enable the ingestion, processing, and delivery of data in real-time. Ultimately, the choice of data streaming platform depends on your specific requirements, such as scalability, real-time processing capabilities, and integration with other services.
Data Streaming vs. Event-Driven Architectures
You might wonder how data streaming differs from event-driven architectures. While both concepts deal with handling real-time data, they have distinct characteristics and use cases.
Data streaming is all about continuous data flow, processing data as it arrives. It focuses on the seamless, real-time movement and processing of large volumes of data from various sources. Think of it as a river of data, constantly flowing and being processed.
In contrast, event-driven architectures are focused on the exchange of events between different components of a system. These events represent significant occurrences in the system, triggering specific actions when they happen. It's like a series of interconnected event triggers and listeners.
The key distinction lies in their primary focus: data streaming is about the continuous flow of data, while event-driven architectures focus on the meaningful events within a system.
Data streaming patterns
Let's talk about some of the most common and useful patterns when building data streaming applications: change data capture, content enricher, content and message filtering, and translator pattern. And finally, you will learn a pattern to ingest log data efficiently.
In this video, you will learn some useful patterns when building data streaming solutions.
Introduction to Amazon Kinesis
Amazon Kinesis is a family of services that is great for real-time big data and building data streaming applications. The Kinesis family offers many services to perform specific tasks and integrates natively with many AWS services.
The services available in the Amazon Kinesis family:
Amazon Kinesis Data Streams: a low latency streaming ingest at scale
Kinesis Data Firehose: allows us to load streams of data into S3, Redshift, and other services
Kinesis Video Streams: allows us to process live video data in real time.
In this video, you will learn the basics from Amazon Kinesis. Why you want to use it? What problem is it solves? Also, the video gets into the details or Amazon Kinesis Data Stream and Amazon Kinesis Firehose.
2- Amazon Kinesis Data Streams
Kinesis Data Streams take the data generated by different producers and ingest them into shards. Then the different consumers will read that data from the shards.
.19b17326a59c73de2f302723b52b63e8399d722f.png)
How Shards works?
Kinesis Data Streams has 2 modes for provision capacity to those shards, on-demand or provisioned. No matter which mode you chose, you are going to have shards. A shard is a unique sequence of data records in a stream and provides a fixed unit of capacity.
Each shard can support 5 read transactions per second or 2 MB per second. And they can write up to a 1000 records per second up to a maximum total write of 1 MB per second.
Inside a shard, you are going to have records. Records are an immutable unit of data stored in a shard. They are composed of a sequence number, a partition key, and a data blob.
The partition key is a value that determines in which shard the record will be stored into. The sequence number is unique per partition key and Kinesis Data Stream will assign it to the record when writing it to the stream. Records are put in order inside the shards, but the order is not guaranteed between the shards.
Capacity mode
If you need to to increase the throughput of your stream, you need more capacity in your stream, to increase that you need more shards. The capacity mode for a stream determines how the capacity is managed in the stream, currently Kinesis Data Stream supports on-demand and provisioned mode.
In this video, you will learn what is Amazon Kinesis Data Streams, what are the shards and how you can use different ways to provision capacity to your stream. At the end of this video, you will see how to create a stream using AWS CDK.
Get the code (make sure that you are in the branch 01-create-stream):
https://github.com/mavi888/cdk-kinesis-data-streaming-demo/tree/01-create-stream
3-Kinesis Data Stream and AWS Lambda
You can use AWS Lambda to consume records from Kinesis and process them on real time or to put records in a stream. AWS Lambda is a great service to integrate with Kinesis Data Streams as it can increase it capacity as needed to support a big load of records coming it way.
In this video, you will learn how to put events into a Kinesis Data Stream from AWS Lambda using AWS SDK and AWS CDK. And in the second half you will learn about consuming events from the stream and triggering functions using Event Source Mapping and AWS Lambda.
Get the code:
https://github.com/mavi888/cdk-kinesis-data-streaming-demo/tree/02-lambda-consume-produce
Advanced Event Source Mapping
Typically, when data stored in a Kinesis data stream is consumed by an application, it is that consumer's responsibility to track-or checkpoint- a stream's last known position that was successfully processed. The event source mapping takes care of checkpointing for you, so your Lambda function code can purely focus on the business logic for processing an event or set of events.
You can consume the records from a Kinesis data stream from Lambda, every time there are records in the stream a function can be triggered. For simplifying that you can use an event source mapping.
An event source mapping is a Lambda resource that reads from an event source and invokes a Lambda function. You can use event source mappings to process items from a stream or queue in services that don’t invoke Lambda functions directly, like DynamoDB, Kinesis, Amazon MQ, MSK, SQS, DocumentDB.
In this video, you will learn most of the features from Event Source Mapping (or ESM).
Trouble shooting ESM
Sometimes things don't work, or even worse they stop working. And how you trouble shoot errors when working with Lambda and Kinesis Data Streams. In this video, Anahit shares with us a lot of strategies on what to do when you are working with Kinesis Data Streams and Lambda and suddenly things stop working. How to trouble shoot your event producer and consumer to figure out where the problem is.
4-Kinesis Data Streams and Amazon EventBridge Pipes
AWS Lambda is not the only way to process and consume records in real time from a stream. Amazon EventBridge Pipes can also consume and process records from the stream and deliver it to different targets.
In this video, you will learn how to create production like data pipelines using Amazon Kinesis Data Streams and EventBridge Pipes. You will learn how to store your analytic data in your data lake, while at the same time process your events as they come in in your Event Bus.
Get the code: https://github.com/mavi888/cdk-kinesis-data-streaming-demo/tree/03-kinesis-pipes
5-Amazon Kinesis Firehose
Kinesis Firehose is a service that helps with the ingestion of data, the processing or transformation of data, and storing it in some destination, like a database or data lake.
Kinesis Firehose is a fully managed service that provides near real-time streaming ETL - extract, transform and load. It scales automatically and it is low cost.
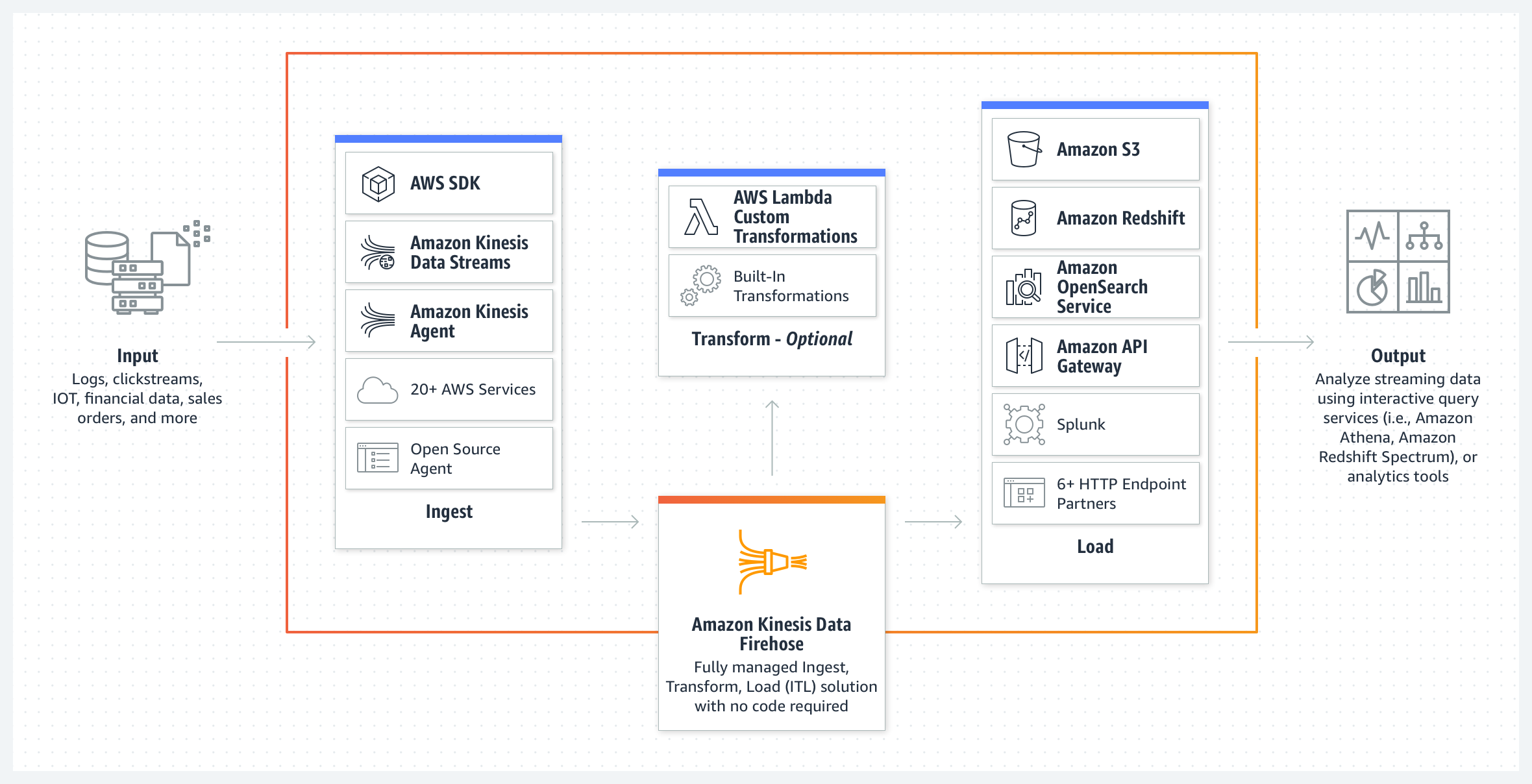
Kinesis Firehose is a ETL, that receives data from different sources. It supports over 20 different sources, like AWS SDK using the Direct Put, Amazon KDS, Kinesis Agent, and many open sources agents.
The transformation of data is optional, but it provides built-in transformations, like converting the data from JSON to Parquet or ORC, dynamic partitioning, and others. And for more complex transformations you can use AWS Lambda.
And finally the last step is the load. In here Kinesis Firehose will store the data into different databases, data lakes, like S3, Redshift, OpenSearch, or you can send to API Gateways or HTTP endpoints to third parties or custom solutions. So you can utilize them later on.
Kinesis Firehose use cases
You can use Kinesis Firehose for different use cases:
Collecting click stream analytics, you can ingest the data in real time and deliver it to your data lakes enabling your marketers to take action on the data.
IoT analytics is a common use case for organisations that use IoT in where they send the data from connected devices and produce near-real time analytics
Event analytics, to understand how much downloads, transactions or other operations your users do.
Log analytics is quite a common use case. In here you can collect all the logs with firehose and then detect application and server errors as they happen and identify the root cause by collecting and monitoring the log data
Security Monitoring is another use case in where the network security logs are sent to firehose and they are monitored in near real time to analyze when there is a potential threat and then notify the security department
Kinesis Firehose characteristics
Kinesis Firehose more relevant features when using S3 as a data source:
You can configure the buffer size and buffer interval. These two parameters allows you to configure how fast data will move from your source to your destination. Buffer size can go from 1MB to 128MB and buffer interval goes from 1 minute to 15 minutes. The first of these thresholds that gets hit will be sending data to S3. Using this parameters you can configure how fast your data gets to S3 and how small your files are in S3.
Convert the data from JSON to Parquet or ORC. Parquet and ORC are more efficient than JSON for storing and for making queries.
Kinesis Firehose provides a way to backup the original records if you want and allows you to register any failure in the transformation.
Dynamic partitioning allows you to continuously partition streaming data by using keys within your data.
Data transformation. With Firehose you can invoke a Lambda function to transform your incoming data and deliver the transformed data to your destinations.
In this video, you will learn what is Kinesis Data Firehose, what is used for, what features it has and how it integrates with AWS Lambda and Amazon S3.
Kinesis Firehose and AWS Lambda
In this video, you will learn how to create a Kinesis Data Firehose with AWS CDK that puts records into S3. You will learn 2 configurations, a basic one that just puts the records and a more advanced one that will transform the records using AWS Lambda as they come in to Firehose before putting them in S3.
Get the code for the simple solution: https://github.com/mavi888/cdk-kinesis-data-streaming-demo/tree/04-kinesis-firehose
Get the code for the advanced solution: https://github.com/mavi888/cdk-kinesis-data-streaming-demo/tree/05-kinesis-firehose-lambda
Conclusion
Congratulations on reaching the end! This guide is quite extensive and not intended to be read all at once.
By now, you have gained knowledge about building data streaming applications with Amazon Kinesis, you learn about the different services that are in the Kinesis family, you learn how to use Kinesis data streams with Lambda and EventBridge Pipes, and how to use Kinesis Firehose with Lambda for doing transformations.
Well done on completing this guide!
Are you looking for a similar guide but for Kafka check it at ServerlessLand



